
MariaDB 自 10.0 版本起,作为引擎独立表统计信息的一部分,就已支持直方图。作为谷歌编程之夏 (MDEV-21130) 的一部分,Michael Okoko 与他的导师 Sergey Petrunia 一起,实现了一种新的直方图格式(使用 JSON),显著提高了直方图的准确性和灵活性。如果只对特性细节感兴趣,可以直接跳到“新格式”部分;但是,如果对直方图的目的不熟悉,请继续阅读。
为什么需要统计信息
对于 WHERE 子句使用未索引列的查询,直方图非常重要。当列未索引时,优化器可用的信息非常有限。
为了更清楚地说明这一点,让我们想象以下情况:我们有两个表 customers 和 orders。假设我们想找出年龄小于 30 且订单金额大于 10000€ 的客户。我们假设每个表都有主键,并且外键也有索引。提供给优化器的查询是
SELECT c.name as 'Customer Name', c.age as 'Customer Age'
o.date as 'Order Date', o.total_sum as 'Order Total Invoice'
FROM customers c JOIN orders o ON customers.id = orders.customer_id
WHERE orders.total_sum >= 10000 and c.age < 30根据商店的类型和销售的商品种类,可能有许多订单符合此查询(例如汽车经销商),或者根本没有(例如旧货店)。这完全取决于数据分布。这意味着查询优化器需要做出选择:是从客户表开始扫描并查找每个订单,还是从订单表开始扫描并查找客户数据?
如果没有列统计信息,优化器将假定所有条件的过滤率为 100%,这意味着所有行都将通过这两个条件。这意味着唯一可行的选择是从较小的表(即客户表)开始。但这并非总是正确的选择。可能只有一小部分订单匹配,在这种情况下,连接所有客户数据然后将其丢弃几乎没有意义。这就是为什么查询优化器需要列统计信息的原因。
旧格式
在 10.0 版本中,MariaDB 引入了通过 ANALYZE TABLE ... PERSISTENT FOR ALL 收集统计信息的支持。其格式是高度平衡(或等高)直方图的二进制表示,大小不能超过 255 字节。此外,直方图精度可以设置为单精度或双精度(每个桶一或两字节)。
这种格式存在多个问题
- 桶边界难以准确定义(特别是对于基于文本的数据)
- 表示方式不够灵活。它无法涵盖其他类型的直方图,例如最常见值直方图。
- 检查直方图数据对用户不友好(即使使用 DECODE_HISTOGRAM 函数)。
- 倾斜数据(例如在大量单个出现中有一个非常常见的值)可能使直方图变得无用。例如,姓名就是这种情况。
- 单精度类型精度有限(只有 255 级),对于大多数分布容易出现舍入误差,即使双精度也仍然受限于 255 * 255 级。
为了说明这些问题,这里有两个使用 MariaDB 的 analyze table 收集的分布,使用了双精度直方图。首先,一个好的用例:一个正态(高斯)分布的值。
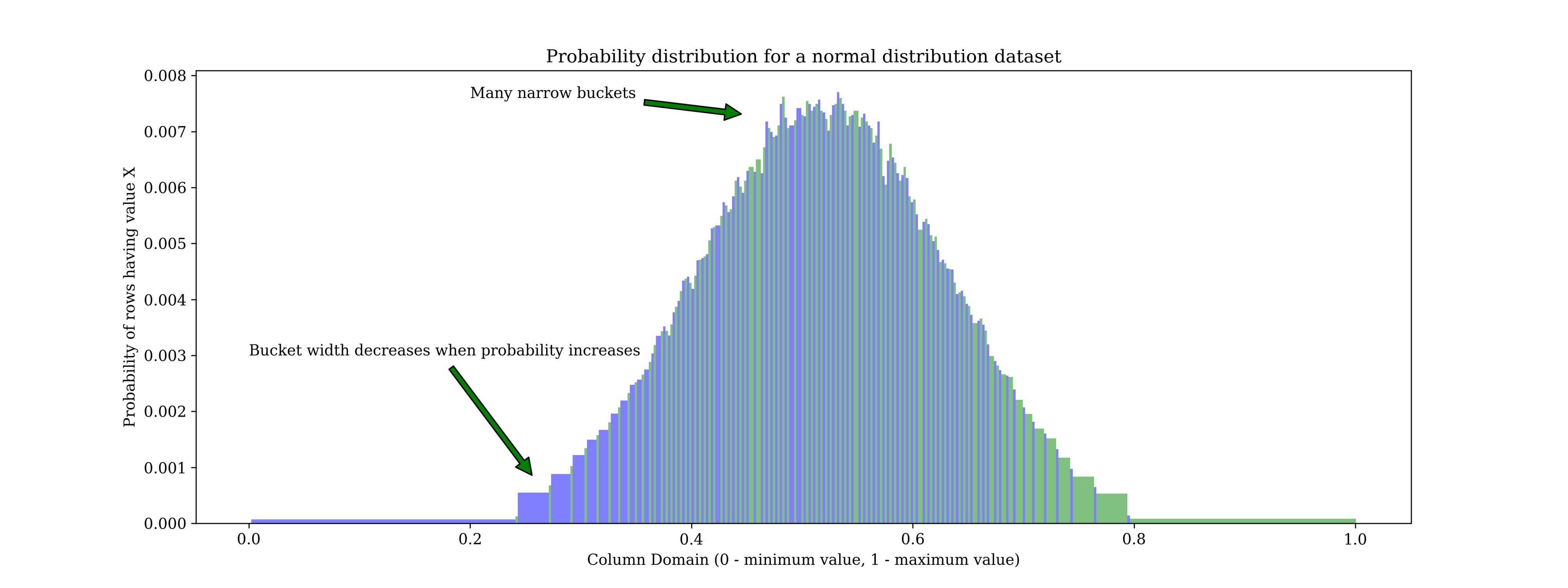
在这里我们可以看到等高直方图的优势。在数据分布较低的地方,覆盖该范围的桶很少。(例如从 0 到 0.2,只有一个桶)。当数据分布在 0.4 和 0.6 数据范围之间增加时,桶变得更窄,为“感兴趣”的区域提供了更高的精度。
现在让我们看看性能不佳的用例:显示姓名概率分布的直方图。

在这里我们可以看到姓名的稀疏性。我们的域从 AARON 开始,到 ZANE 结束,但在其间有许多潜在的无效姓名,如 AARPN 或 ZAME 或 ZAAZBBB。这种表示无法解释这种情况。我们甚至会看到一些伪影,在峰值之间出现均匀分布。
新格式
考虑到旧格式的局限性,我们决定引入一种使用 JSON 的更灵活的表示方式。让我们看看这些变化
首先,mysql.column_stats 表的 histogram 列类型已更改为 blob,以便可以同时涵盖旧格式和新格式。type 列现在接受 JSON_HB。系统变量 histogram_type 接受此新类型。当类型设置为 JSON_HB 时,变量 histogram_size 指定直方图将包含的桶数量。
直方图本身现在看起来像这样(本例中有 3 个桶)
{
"histogram_hb_v2": [
{
"start": "Berlin",
"size": 0.333333333,
"ndv": 1
},
{
"start": "Paris",
"size": 0.333333333,
"ndv": 1
},
{
"start": "Rome",
"end": "Rome",
"size": 0.333333333,
"ndv": 1
}
]
}key 用于标识直方图的版本。这在未来的 MariaDB 版本中会发生变化。对于这个特定版本,数据是一个桶数组。每个桶指定直方图桶的 start。这是适合该桶的数据范围中的第一个值。end 值仅为最后一个桶指定,因为对于前面的桶,优化器使用后续桶的 start 作为当前桶的 end。
然后我们有 size,它表示适合此桶的行数占总表行数的比例。对于大多数数据集,所有桶的大小往往相同(或非常接近),但如果存在一个非常常见的值,它将拥有自己的桶,并且可能占总表行数的更大比例。对于这些桶,您会注意到 ndv(即适合该桶的不同值的总数)设置为 1。
如果我们比较我们的姓名示例的性能
使用旧表示,查看 filtered 列以查看直方图预测的行百分比,查看 r_filtered 以查看查询实际返回的行百分比
MariaDB [statistics]> analyze select * from t2 where names = 'John';
+...+-------------+-------+...+--------+-----------+----------+------------+
|...| select_type | table |...| rows | r_rows | filtered | r_filtered |
+...+-------------+-------+...+--------+-----------+----------+------------+
|...| SIMPLE | t2 |...| 100000 | 100000.00 | 5.47 | 3.63 |
+...+-------------+-------+...+--------+-----------+----------+------------+
1 row in set (1.141 sec)使用 JSON 表示
MariaDB [statistics]> analyze select * from t2 where names = 'John';
+...+-------------+-------+...+--------+-----------+----------+------------+
|...| select_type | table |...| rows | r_rows | filtered | r_filtered |
+...+-------------+-------+...+--------+-----------+----------+------------+
|...| SIMPLE | t2 |...| 100000 | 100000.00 | 3.63 | 3.63 |
+...+-------------+-------+...+--------+-----------+----------+------------+所以对于 John,旧直方图看起来还不错。它不精确,但偏差不大。然而,让我们尝试 Joan,一个与 John 非常接近的姓名。
使用旧表示
MariaDB [statistics]> analyze select * from t2 where names = 'Joan';
+...+-------------+-------+...+--------+-----------+----------+------------+
|...| select_type | table |...| rows | r_rows | filtered | r_filtered |
+...+-------------+-------+...+--------+-----------+----------+------------+
|...| SIMPLE | t2 |...| 100000 | 100000.00 | 5.47 | 0.01 |
+...+-------------+-------+...+--------+-----------+----------+------------+使用 JSON 表示
MariaDB [statistics]> analyze select * from t2 where names = 'Joan';
+...+-------------+-------+...+--------+-----------+----------+------------+
|...| select_type | table |...| rows | r_rows | filtered | r_filtered |
+...+-------------+-------+...+--------+-----------+----------+------------+
|...| SIMPLE | t2 |...| 100000 | 100000.00 | 0.08 | 0.01 |
+...+-------------+-------+...+--------+-----------+----------+------------+
1 row in set (1.141 sec)这里我们就看到了区别!对于旧格式,Joan 和 John 落入同一个桶,因此产生相同的估算值,其中一个严重偏离。(5% 而不是 0.01%)。新格式将误差降低到 0.08%,提高了两个数量级!
我们相信这项特性将有助于提高优化器在许多用例中的整体性能。我们现在特别期待反馈,趁热打铁,我们可以解决可能忽略的任何局限性。请告知我们使用新直方图以及您的数据和查询时,优化器表现如何!
如何亲自试用 10.7 JSON 直方图?
Tarball 包
前往 tarball 下载。
容器
为了尽可能轻松地测试此预览版,您可以运行名为 quay.io/mariadb-foundation/mariadb-devel:10.7-mdev-26519-improved-json-histograms 的容器,其接口与 Docker Library mariadb 镜像相同。
欢迎提供反馈
如果您在此特性预览版中遇到任何问题,无论是在设计方面还是存在未按预期工作的边缘情况,请通过 JIRA 在 MDEV 项目中提交错误/特性请求告知我们。欢迎在 Zulip 上进行讨论。
另请参阅知识库页面了解更多详情。