分类归档: 生成式AI

我很高兴受邀在瑞典哥德堡的 foss-north 2025 会议上演讲关于“利用您自己的数据通过 RAG 使 AI 透明化”。4 月 14 日在查尔姆斯理工大学,我在满座的听众面前分享了如何使用 MariaDB Vector 进行 AI RAG,从一个关于使用生成式AI扩展维基百科编辑的用例开始。
使用 RAG 改进维基百科
我分享了一个用例,基于我使用生成式AI为非营利组织 Projekt Fredrika 大规模编辑维基百科的经验。
…

周五,我们很高兴与所有提交了 MariaDB AI RAG 黑客马拉松创意阶段申请的人进行了单独通话。
创意阶段的截止日期已于上周过去,我们很高兴地分享,我们收到了几个很有前景的申请,分别提交给了创新赛道和集成赛道。创新赛道涉及使用 MariaDB Vector 的应用,例如 RAG;而集成赛道则是将 MariaDB Vector 集成到现有框架中。
参与者包括个人贡献者,甚至还有企业团队。有些人已经有AI经验,有些人则是 RAG 的新手。
…
MariaDB AI RAG 黑客马拉松的创意阶段截止日期临近,截止时间是周一(三月底前)。
到目前为止,我们已经收到了几个很棒的提交项目。其中一个是关于结合知识图谱和 LLM,使用了 MariaDB Vector 的最近邻搜索功能。另一个是关于一个“高级上下文差异”功能,它根据内容的含义而不是字面措辞来识别两个文本语料库之间的差异。
目前所有的提交项目都属于创新赛道。我们尤其希望看到集成赛道的提交项目——即将 MariaDB 集成到现有框架(例如 这些)或其他应用中。
…
使用 MariaDB Vector 和 Python 参加 AI RAG 黑客马拉松还剩一周时间!
获胜者将在五月的 赫尔辛基 Python Meetup 上进行演示,获得 MariaDB 基金会和 Open Ocean Capital 的认可和宣传,以及芬兰 verkkokauppa.com 提供的奖品。
要参与,请组建一个团队(1-5 人),并在三月底前针对两个赛道之一提交一个创意。然后你们有时间到 5 月 5 日来开发这个创意,并在 5 月 27 日的 Meetup 之前完成。
- 集成赛道: 在现有开源项目或 AI 框架中启用 MariaDB Vector。
…
我们很高兴宣布一项使用 MariaDB Vector 和 Python 的黑客马拉松。鉴于我们正在扩展我们的范围,让我们从头开始:
MariaDB,这个开源数据库为世界上要求最苛刻的应用提供支持,从维基百科到全球金融机构。现在,MariaDB Vector 将支持 AI 的向量搜索原生带入开源数据库世界。MySQL 用户请注意:
我们的黑客马拉松是您使用 MariaDB Vector 和 Python 探索 AI 可能性的机会。无论您是开发者、数据科学家还是 AI 爱好者,MariaDB 基金会邀请您构建创新的 AI 应用,角逐奖品,并展示您的成果。
…

从布鲁塞尔回来了!稍作思考后,我想分享一下我们 MariaDB Day(我们自己的 FOSDEM 周边活动)的会后回味。请准备好阅读这篇信息量很大的博客文章,其中包含演讲的链接,包括 现场录像,通常还有幻灯片。
亿万富翁争议取消
二月的第一个周末,布鲁塞尔是开源的热点聚集地。天气可能不热,但与 ULB 大学走廊和房间里热烈的讨论形成鲜明对比。预期中最热门的话题——抵制 Twitter 创始人 Jack Dorsey 的演讲——实际上并未发生。
…

我们不是读心术者,所以我们不时会进行投票。投票本质上是定量的,因此,仅仅提出正确的问题是不够的——在提出备选项时,我们需要做一些“读心”工作。
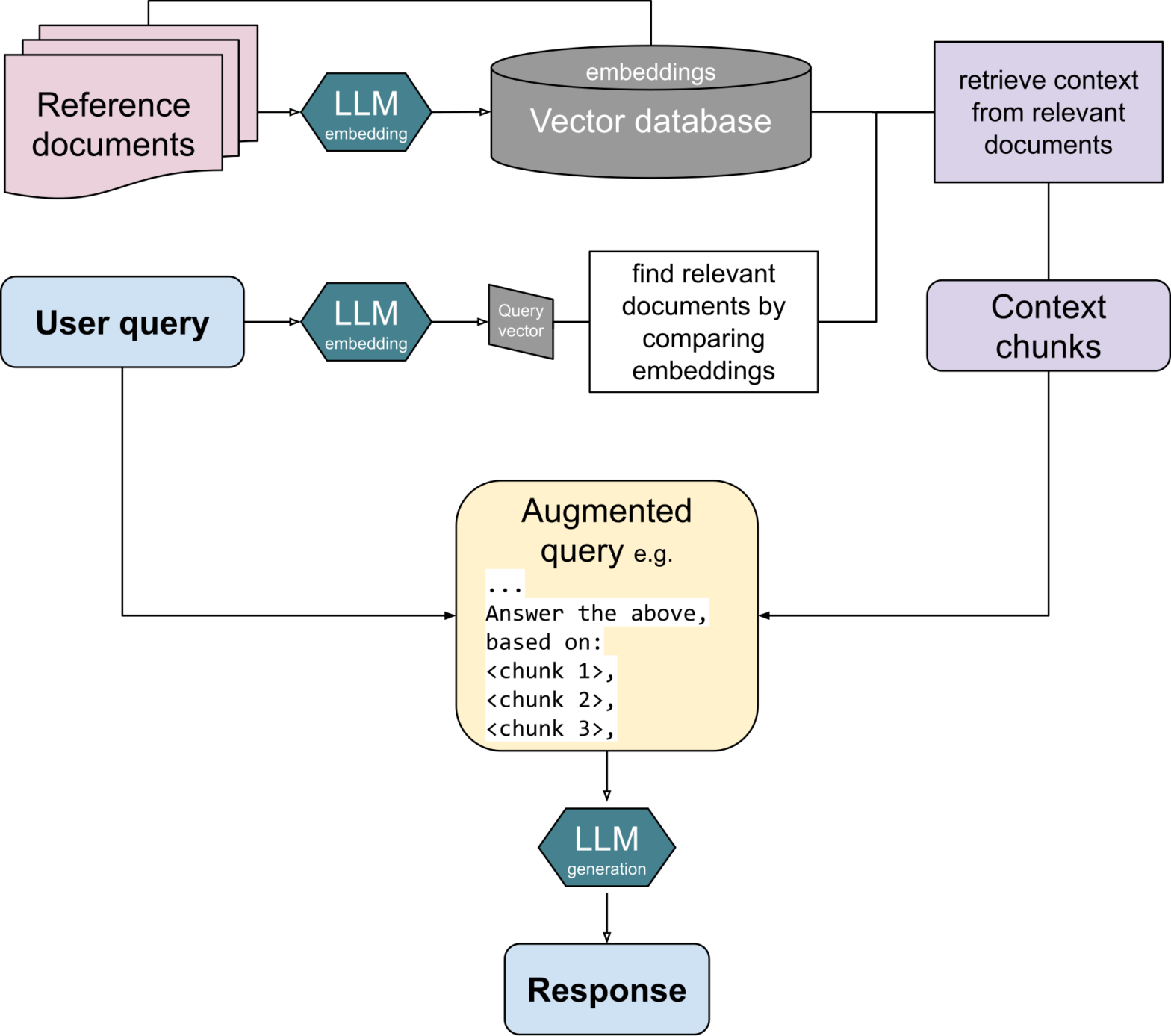
快速开发基于文本的 RAG 应用
我们的假设是,RAG 是使用向量数据库(特别是基于文本的 RAG)的热门方向。我们在关于 MariaDB Vector 的会议演讲中(例如 2024 年 11 月 8 日在意大利南蒂罗尔博尔扎诺举行的第 24 届 SFSCON 上)强调了能够轻松开发 AI 应用的价值,这些应用能够根据特定文本集中的知识来回答用户提示,而不是基于 LLM 的整体训练数据。
…