
如何调优 MariaDB 的写入性能
本文介绍了我是如何调优 MariaDB,以便在基于 SSD 的存储上获得最佳的写入吞吐量。
当你有一个写操作繁重的应用程序向 InnoDB 写入数据时,你可能会遇到 InnoDB Checkpoint Blues。这种效应表现为停顿——吞吐量短暂降至零,I/O 活动异常繁忙。这种现象众所周知,例如此处有所描述。关于检查点的更多背景信息可以在此处找到。
XtraDB 是 InnoDB 引擎的一个分支(也是Percona Server的核心),它包含了一些旨在克服这种异常行为的补丁。MariaDB 使用 XtraDB 作为默认的 InnoDB 实现,因此我们可以配置一些额外的变量,有望避免检查点停顿问题。
第一个也是最重要的设置是 innodb_io_capacity。这是你的硬件能够执行的近似写入操作次数。如果你不知道这个数字,可以很容易地找到。等到你遇到停顿,然后运行 iostat -x。你应该在存放 InnoDB 表空间设备的 wrqm/s 和 w/s 上看到相当高的数字。W/s 是到达设备的写入请求数,wrqm/s 是可以合并的请求数。两者的总和是 InnoDB 实际使用的数量。
在我的例子中,磁盘是 3 个 SAS SSD 组成的 RAID-0,我曾看到高达每秒 25,000 次写入。因此我设置 innodb_io_capacity=20000,并将其他所有设置保持默认。

这里我们已经可以看到停顿消失了。然而,在大约 370 秒后,我们看到了一个相当大的 I/O 峰值。这是当检查点年龄达到日志组容量的 75% 时,XtraDB 开始积极刷新的结果。
现在让我们看看能否做得更好。Percona Server 文档声称: innodb_adaptive_flushing_method=keep_average: … 设计用于 SSD 卡。所以接下来我们尝试这个设置。
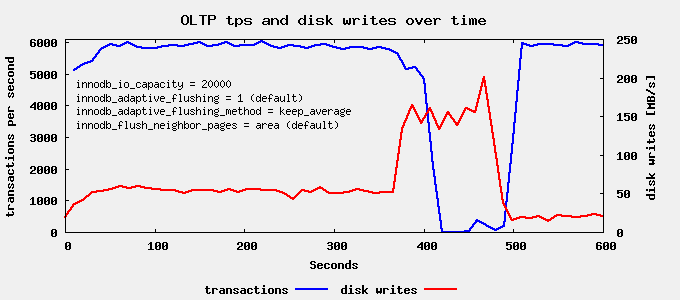
失败! 让我们快速将其恢复到默认设置。
接下来要看的是邻居页刷新(neighbor page flushing)。它的工作原理是这样的:InnoDB 页面以 64 页为单位组织成块。当检查点算法选择了一个脏页要写入磁盘时,它会检查该块中是否还有其他脏页,如果有,则一次性写入所有这些页面。其基本原理是,对于旋转磁盘,写入操作中最昂贵的部分是磁头移动。一旦磁头定位到正确的磁道上,写入 10 个扇区还是 100 个扇区并没有太大区别。
默认设置是 innodb_flush_neighbor_pages=area。然而对于 SSD,没有磁头移动的开销。因此尝试其他设置是有意义的。接下来让我们尝试 innodb_flush_neighbor_pages = cont。
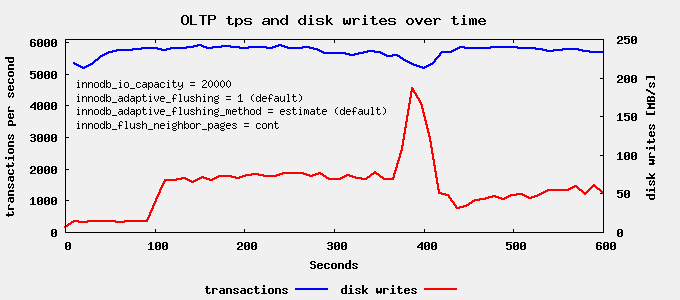
我们仍然在运行时长约 400 秒时看到一个写入峰值,但这比上次不那么明显。现在我们最后尝试 innodb_flush_neighbor_pages=none。
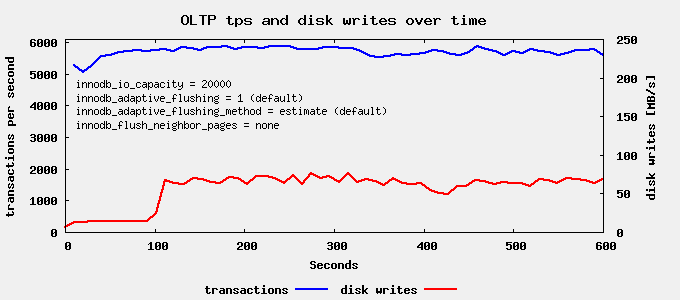
终于成功了!对于基于 SSD 的存储,最佳的参数组合似乎是:innodb_flush_neighbor_pages = none,innodb_io_capacity = 你的硬件能够做到的值,以及其他所有设置保持默认。
如果存储使用旋转磁盘,我们可能最好使用 innodb_flush_neighbor_pages = cont 甚至 innodb_flush_neighbor_pages = area,但目前我没有硬件进行测试。
免责声明:上面的图表使用了 sysbench OLTP 多表读/写基准测试。数据集大小为 10G,InnoDB 缓冲池为 16G,InnoDB 总日志容量为 4G。
我认为如果你能添加一张包含 innodb_io_capacity 默认值 (200) 的图表,那将更好地展示这个设置的重要性。