

机器学习是一个没有数据就无法成功的领域。传统上,机器学习框架从 CSV 文件或类似的数据源读取数据。这带来了一系列有趣的挑战,因为在大多数情况下,数据存储在数据库中,而不是简单的原始文件。将数据从一种格式移动到另一种格式需要时间和精力。此外,还需要编写一些代码(通常是 python)来按照 ML 框架期望的方式准备数据。
在 MariaDB Server Fest 期间,当我看到 MindsDB(一个自动化机器学习系统)展示了他们与 MariaDB 的集成时,我感到惊喜。我决定试一试,由于我有人工智能背景,我想我会在 kaggle.com 上使用一个挑战来测试它。很久以前我做过一个挑战,根据天气条件(如温度、风和一天中的时间)预测租赁自行车骑行的数量。
我的目标是看看是否可以使用 MindsDB 和 MariaDB 获得不错的结果(显著优于基线),而无需主动接触机器学习框架或进行特征工程、数据增强等技巧。
注意,这篇文章不是一个简单的分步教程。相反,我还深入探讨了一点来解释事物是如何工作的。
排除所有障碍,让我们继续进行实验吧!
初始设置
要使系统工作,需要准备一些东西。我将尝试解释我运行的命令,但根据您的 Linux 发行版或您使用的不同操作系统(如 Windows 或 OS X),它们可能会略有不同。
首先,我安装了 MariaDB。我碰巧使用的是 MariaDB 的开发版本(10.6),但这应该不会对结果产生任何影响。有很多关于如何安装 MariaDB 的教程。对我来说最简单的方法是通过仓库配置工具。
MindsDB 文档建议在 MariaDB 中使用 root 用户以便轻松设置,但我想看看它实际需要哪些权限。所以我创建了一个用户 mindsdb@localhost,并设置了密码。为了让它工作,我授予了全局的 FILE 权限和 mindsdb 数据库上的所有权限。
CREATE USER mindsdb@localhost;
SET PASSWORD for mindsdb@localhost=PASSWORD("password");
GRANT FILE on *.* to mindsdb@localhost;
GRANT ALL on mindsdb.* to mindsdb@localhost;
其次,我安装了 MindsDB。因为它是用 Python 编写的,并且我想保持系统干净,我更喜欢使用虚拟环境。因此,我创建了一个虚拟环境并使用 pip 安装了 MindsDB。
mkdir ~/mindsdb/ && cd ~/mindsdb/ && virtualenv venv -p python3 pip install mindsdb
MindsDB 使用了很多外部模块,所以这花了一些时间。安装完成后,我们几乎就可以开始了。最后一步是配置 MindsDB 以连接到正确的 MariaDB 服务器。
MindsDB 接受一个 JSON 配置文件。这是我使用的那个
{
"api": {
"http": {
"host": "0.0.0.0",
"port": "47334"
},
"mysql": {
"host": "127.0.0.1",
"log": {
"console_level": "INFO",
"file": "mysql.log",
"file_level": "INFO",
"folder": "logs/",
"format": "%(asctime)s - %(levelname)s - %(message)s"
},
"port": "47335",
"user": "root"
"password": "password",
}
},
"config_version": "1.2",
"debug": true,
"integrations": {
"default_mariadb": {
"enabled": true,
"host": "localhost",
"password": "root",
"port": 3306,
"type": "mariadb",
"user": "root"
}
},
"interface": {
"datastore": {
"enabled": true
},
"mindsdb_native": {
"enabled": true
}
},
"storage_dir": "/home/vicentiu/Workspace/MindsDB/datastore"
}
配置好这个文件后,需要启动 MindsDB。使用虚拟环境
source venv/bin/activate python -m mindsdb --config=./config.json --api=http,mysql
MindsDB 的工作方式相当有趣。一方面,它连接到 MariaDB 服务器以创建一些特殊表,称为 AI 表。连接详细信息在配置文件的“integrations”部分指定。这些 AI 表实际上是使用 CONNECT 引擎连接到外部数据库的表。另一方面,这个外部数据库实际上就是 MindsDB 本身!让我们看看这些 AI 表
MariaDB> SHOW DATABASES; +--------------------+ | Database | +--------------------+ | information_schema | | mindsdb | | mysql | | performance_schema | | test | +--------------------+ MariaDB> USE mindsdb; MariaDB> SHOW CREATE TABLE commands\G CREATE TABLE `commands` ( `command` varchar(500) DEFAULT NULL ) ENGINE=CONNECT DEFAULT CHARSET=latin1 CONNECTION='mysql://root_default_mariadb:password@127.0.0.1:47335/mindsdb/commands' `TABLE_TYPE`=MYSQL
注意 commands 表:它连接到配置文件中指定的端口 47335 上的 MindsDB。在这种情况下,MindsDB 正在伪装成一个 MySQL/MariaDB 服务器!这就是 MariaDB 能够从 MindsDB 获取信息的方式。
数据
现在系统已经运行起来了,是时候进行测试了。我提到的 Kaggle 挑战的训练数据是一个 CSV 文件。我为这些数据创建了一个表,并使用 LOAD DATA INFILE 填充了它。
MariaDB> USE test;
MariaDB> CREATE TABLE test.`bike_data` (
`datetime` datetime DEFAULT NULL,
`season` int(11) DEFAULT NULL,
`holiday` int(11) DEFAULT NULL,
`workingday` int(11) DEFAULT NULL,
`weather` int(11) DEFAULT NULL,
`temp` double DEFAULT NULL,
`atemp` double DEFAULT NULL,
`humidity` double DEFAULT NULL,
`windspeed` double DEFAULT NULL,
`casual` int(11) DEFAULT NULL,
`count` int(11) DEFAULT NULL);
MariaDB> LOAD DATA INFILE '/home/vicentiu/Downloads/train.csv'
INTO TABLE bike_data columns terminated by ',';
注意: LOAD DATA INFILE 会尝试插入第一行,即表头。我在加载之前从文件中删除了这一行。
训练模型
最后,我们可以让 MindsDB 开始训练。要开始训练,只需向 AI 表插入一个 INSERT 命令即可
INSERT INTO `predictors`
(`name`, `predict`, `select_data_query`)
VALUES ('bikes_model', 'count', 'SELECT * FROM test.bike_data');
这个命令的作用是告诉 MindsDB 创建一个名为“bikes_model”的预测模型,并预测“counts”列。用于创建模型的数据是通过 SELECT 查询 SELECT * FROM test.bike_data 获取的。30 分钟后,模型训练完成。
模型训练完成后,MindsDB 会在 MariaDB 的 mindsdb 数据库中创建另一个表。这个表与模型的名称相同(bikes_model),并且同样被设置为一个 CONNECT 表。
检查模型
还记得启动 MindsDB 时使用的 --api=http 吗?那是用来启动 MindsDB Scout 的,一个用于检查模型性能的图形化网页工具。它可以通过配置文件中指定的端口访问 (http://0.0.0.0:47334)
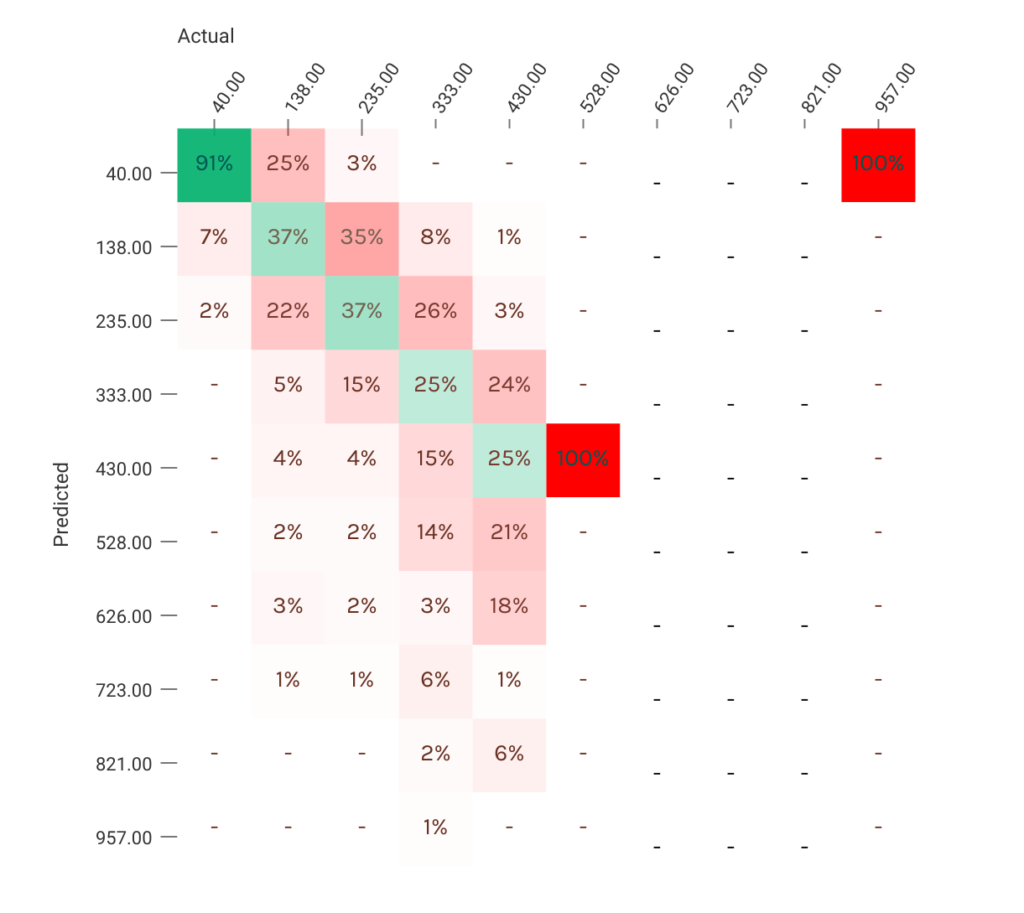
混淆矩阵提供了一些关于模型在哪些方面表现强劲,哪些方面表现薄弱的见解。
使用模型
最后一步是进行预测。要运行预测,必须从与先前训练的模型匹配的表中进行 SELECT 查询。
MariaDB> SELECT count, count_confidence
FROM mindsdb.bikes_model
WHERE datetime='2011-01-20 00:00:00' AND
season='1' AND
holiday='0' AND
workingday='1' AND
weather='1' AND
temp='10.66' AND
atemp='11.365' AND
humidity='56' AND
windspeed='26.0027';
+-------+------------------+
| count | count_confidence |
+-------+------------------+
| 33 | 0.9675 |
+-------+------------------+
MindsDB 用于预测值的参数在 WHERE 子句中。我尝试了不同的参数传递方式,但目前只适用于固定值。传递非确定性函数(如 RAND)或单独的列不起作用。然而,简单的算术和常数函数是有效的,因为 MariaDB 的优化器会在将整个查询传递给 CONNECT 引擎之前将算术替换为常数值。(要查看其工作原理,您可以在 SELECT 查询上使用 EXPLAIN FORMAT=JSON)。
最终评分
为了生成 Kaggle.com 测试集的所有预测结果,我编写了一个简短的 python 脚本来生成所有必需的 SELECT 查询(每个测试用例一个)。之后进行一些文本编辑技巧,将输出格式化为 Kaggle 要求的方式,然后我生成了提交文件。
最终分数将 MindsDB 置于比赛得分的中间位置。基线分数约为 1.5,分数越低越好。我付出了很多努力,最好成绩是 0.5,而 MindsDB 的表现相当不错,分数达到了 0.9。我相信,只要再努力一些,也许进行一些特征增强并针对不同季节训练不同的模型,我可以帮助 MindsDB 的 AutoML 功能更接近我的最好成绩。
话虽如此,我并没有期望 MindsDB 能够超越我的分数,而是希望它能够在不使用数据科学技巧的情况下,提供一个“足够好”的结果。从这个角度来说,我认为这个实验是成功的!
尝试在 MariaDB 中进行 AI 后的一些未来想法
- 可以配置 MindsDB 表创建的位置。不使用硬编码的名为“mindsdb”的数据库会更好。
- 通过 SQL 公开更多关于训练过程和结果的反馈会很有用。例如,MindsDB 在命令行输出训练进度,如训练轮次、模型架构等。通过 AI 表公开这些信息(以及任何其他相关细节)可以帮助用户调试和微调他们的数据。
- 可能比较困难的一个:训练模型并通过流式数据(例如通过读取复制日志)使其保持最新。
直接从 MariaDB 中使用机器学习对于任何希望使用 MariaDB 作为首选数据库的应用程序开发人员来说都是一个宝贵的工具。启动所有组件需要一些工作,但这只需要做一次。之后,任何 ORM 框架或数据库通信库都应该可以正常工作,因为它只是在幕后运行 SQL 查询。期待听到更多关于这个领域未来发展的消息!