
您一直在等待的那一天终于来了,自从 ChatGPT 热潮兴起以来:您现在可以使用您自己的 MariaDB Server 中的数据构建创意 AI 应用程序!通过创建您自己的数据的嵌入并将其存储在您自己的 MariaDB Server 中,您可以开发 RAG 解决方案,其中 LLM 可以根据您自己特定的数据作为上下文来高效执行提示。
为什么选择 RAG?
检索增强生成(RAG)能够根据您自己选择的数据(例如您自己的手册、文章或其他文本语料)创建更准确、基于事实的 GenAI 回答。与一般的大型语言模型(LLM)相比,RAG 的回答更准确、更基于事实,而无需训练或微调模型。
为什么选择与 MariaDB 结合使用 RAG?
RAG 现在可以通过 MariaDB 内置的向量存储和搜索功能实现。从版本 11.7.1 开始,MariaDB 独特地允许用户在同一数据库中整合传统数据查询和基于向量的搜索。
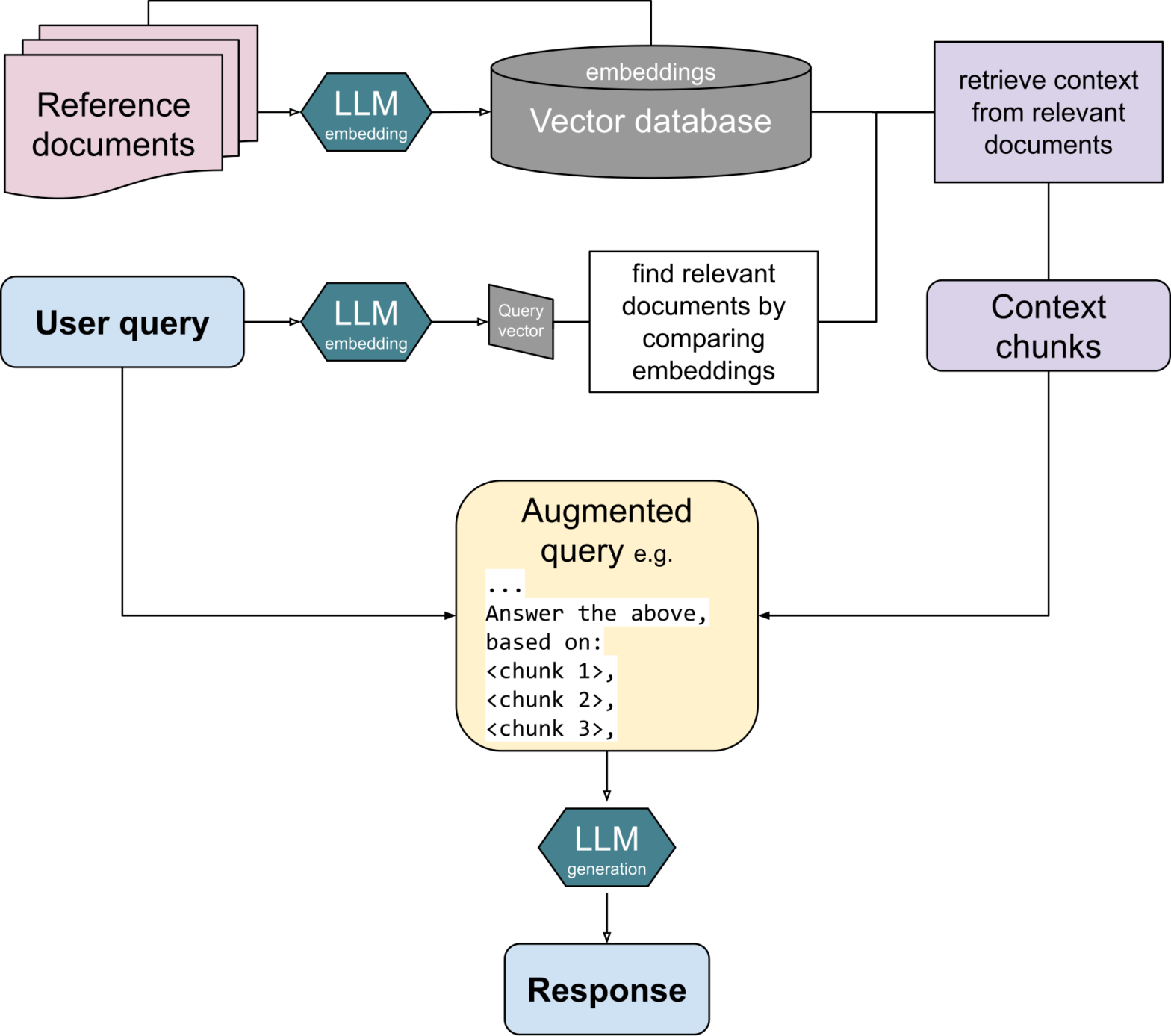
为了展示 MariaDB 中向量的潜力,我将演示如何将 RAG 应用到 MariaDB Knowledge Base (https://mariadb.com/kb)。我将通过代码示例介绍 RAG 的两个主要步骤是
- 准备 / 向量索引创建:每段文本内容通过嵌入模型运行,并将生成的向量插入到 MariaDB 表中。
- 运行 / 向量索引搜索
2.1 当用户输入问题或提示时,它也会使用相同的嵌入模型进行向量化。在 MariaDB 中执行最近邻搜索以找到与输入最接近的内容。
2.2 为了生成响应,用户输入和最接近的内容一起发送给 LLM,以便为用户生成响应。
我现在将使用我们的示例代码(可在 github 上获取)解释 RAG,末尾附有示例输出。
准备 / 向量索引创建
在这个 RAG 示例中,准备工作的目标是为内容及其向量化格式(称为嵌入)创建一个 MariaDB 表。 首先您需要:
- 通过安装 Docker 并运行
docker run -p 127.0.0.1:3306:3306 --name mdb_117 -e MARIADB_ROOT_PASSWORD=Password123! -d mariadb:11.7-rc来设置包含向量功能的 MariaDB 11.7。 - 创建一个 OpenAI API 密钥。在 https://platform.openai.com/api-keys 创建一个,并使用
export OPENAI_API_KEY='your-key-here'将其添加到系统变量中。 - 然后,要使用 python 创建表,您可以使用下面的代码以及
CREATE DATABASE和CREATE TABLE语句。数据类型VECTOR(1536)中的数字表示向量的维度。“向量长度”1536 等同于我们将使用的 OpenAI 的 text-embedding-3-small 模型。
import mariadb
from openai import OpenAI
import json
import os
conn = mariadb.connect(
host="127.0.0.1",
port=3306,
user="root",
password="Password123!"
)
cur = conn.cursor()
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
def prepare_database():
print("Create database and table")
cur.execute("""
CREATE DATABASE kb_rag;
""")
cur.execute("""
CREATE TABLE kb_rag.content (
title VARCHAR(255) NOT NULL,
url VARCHAR(255) NOT NULL,
content LONGTEXT NOT NULL,
embedding VECTOR(1536) NOT NULL,
VECTOR INDEX (embedding)
);
""")
prepare_database()准备好数据库后,通过将内容发送到 OpenAI 的嵌入模型并将其插入到 MariaDB 表中来为您的内容创建嵌入。 下面的代码
- 读取一个包含 6000 多个 MariaDB Knowledge Base markdown 页面 的 jsonl 文件。该文件之前已被抓取,并与示例代码一起提供在同一个 Github 仓库中。 (默认选择包含 20 个 KB 页面的摘要版本。要处理 6000 多个页面,请更改为“完整”文件。)
- 将长页面切割成更短的“块”。这是为了适应嵌入模型 8192 个 token 的最大大小(大约相当于 32,000 个字符)。在这个示例中,页面按标题或段落分割成块,以使每个块的内容更均匀,从而提供更准确的向量表示。
- 使用 OpenAI 的嵌入模型对每个块进行向量化。
- 使用
INSERT语句将块的内容和向量插入到数据库表中。在这个示例中,我们使用 MariaDB 的VEC_FromText()函数将嵌入的字符串表示str(embedding)转换为 MariaDB 中的新向量类型。
def read_kb_from_file(filename):
with open(filename, "r") as file:
return [json.loads(line) for line in file]
# chunkify by paragraphs, headers, etc.
def chunkify(content, min_chars=1000, max_chars=10000):
lines = content.split('\n')
chunks, chunk, length, start = [], [], 0, 0
for i, line in enumerate(lines + [""]): # Add sentinel line for final chunk
if (chunk and (line.lstrip().startswith('#') or not line.strip() or length + len(line) > max_chars)
and length >= min_chars):
chunks.append({'content': '\n'.join(chunk).strip(), 'start_line': start, 'end_line': i - 1})
chunk, length, start = [], 0, i
chunk.append(line)
length += len(line) + 1
return chunks
def embed(text):
response = client.embeddings.create(
input = text,
model = "text-embedding-3-small" # max 8192 tokens (roughly 32k chars)
)
return response.data[0].embedding
def insert_kb_into_db():
kb_pages = read_kb_from_file("kb_scraped_md_excerpt.jsonl") # change to _full.jsonl for 6000+ KB pages
for p in kb_pages:
chunks = chunkify(p["content"])
for chunk in chunks:
print(f"Embedding chunk (length {len(chunk["content"])}) from '{p["title"]}'")
embedding = embed(chunk["content"])
cur.execute("""INSERT INTO kb_rag.content (title, url, content, embedding)
VALUES (%s, %s, %s, VEC_FromText(%s))""",
(p["title"], p["url"], chunk["content"], str(embedding)))
conn.commit()
insert_kb_into_db()运行 / 向量索引搜索
当准备对用户的输入做出响应时,下面的代码执行以下操作
- 对用户的输入进行向量化。向量化需要使用与准备阶段相同的嵌入模型进行。
- 在 MariaDB 中执行最近邻搜索,查找与用户输入最接近的内容。在这个示例中,我们不将结果限制为仅一个“块”,而是获取排名前 5 的块。
def search_for_closest_content(text, n):
embedding = embed(text) # using same embedding model as in preparations
cur.execute("""
SELECT title, url, content,
VEC_DISTANCE_EUCLIDEAN(embedding, VEC_FromText(%s)) AS distance
FROM kb_rag.content
ORDER BY distance ASC
LIMIT %s;
""", (str(embedding), n))
closest_content = [
{"title": title, "url": url, "content": content, "distance": distance}
for title, url, content, distance in cur
]
return closest_content
user_input = "Can MariaDB be used instead of an Oracle database?"
print(f"User input:\n'{user_input}'")
closest_content = search_for_closest_content(user_input, 5)为了生成对用户输入的实际响应,下面的代码执行以下操作
- 将用户的输入问题以及最相关的块内容一起作为提示发送给 OpenAI 的 LLM。提示中还包含 LLM 如何响应的说明。该提示以文本形式发送到 OpenAI 的 API。
- 打印 LLM 的响应。在 有 RAG 上下文和 没有 RAG 上下文的情况下,LLM 的响应方式有所不同。没有上下文的响应容易产生幻觉。下面的代码打印出两种响应,以便我们能看到差异。
def prompt_chat(system_prompt, prompt):
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
],
)
return response.choices[0].message.content
system_prompt_with_rag = """
You are a helpful assistant that answers questions using exclusively content from the MariaDB Knowledge Base that you are provided with.
End your answer with a link to the most relevant content given to you.
"""
prompt_with_rag = f"""
The user asked: '{user_input}'.
Relevant content from the MariaDB Knowledge Base:
'{str(closest_content)}'
"""
print(
f"""
LLM response with RAG:'
{prompt_chat(system_prompt_with_rag,prompt_with_rag)}'
"""
)
system_prompt_no_rag = """
You are a helpful assistant that only answers questions about MariaDB.
End your answer with a link to a relevant source.
"""
prompt_no_rag = f"""
The user asked: '{user_input}'.
"""
print(
f"""
LLM response without RAG:
'{prompt_chat(system_prompt_no_rag, prompt_no_rag)}'
"""
)下面是针对问题“MariaDB 可以用来替代 Oracle 数据库吗?”运行整个脚本时的输出。
带有 RAG 上下文的 LLM 回答是事实且切题的,并提供了从提供的内容中可靠获取的源 URL。
没有 RAG 上下文的 LLM 回答则“编造”了一个没有多少实际内容的回答,并创建了一个听起来似乎合理但实际不存在的源 URL。
User input: 'Can MariaDB be used instead of an Oracle database?' LLM response with RAG: 'Yes, MariaDB can be used instead of an Oracle database, especially with features like the `SQL_MODE='ORACLE'`, which allows for compatibility with Oracle SQL syntax and behavior. This makes it easier for organizations to migrate applications from Oracle Database to MariaDB while preserving existing SQL scripts and application logic. For more detailed information, you can refer to the following link: [SQL_MODE=ORACLE](https://mariadb.com/kb/en/sql_modeoracle/).' LLM response without RAG: 'Yes, MariaDB can be used as an alternative to an Oracle database in many scenarios, especially for applications that require relational database management. However, it is important to evaluate the specific needs of your application, as there may be differences in features, performance, and compatibility. For more detailed information about the differences between MariaDB and Oracle, you can refer to the official MariaDB documentation here: [MariaDB vs Oracle](https://mariadb.com/kb/en/mariadb-vs-oracle/).'
这就是 MariaDB 与 RAG 结合的基本思路。我们期待听到更多关于在您自己的数据上进行的测试和使用案例。
资源
- GitHub 中提供的代码示例和抓取的知识库: https://github.com/MariaDB/demos/mariadb-kb-rag/
- MariaDB Vector 概述: https://mariadb.com/kb/en/vector-overview/
- 通过 Docker 安装和使用 MariaDB https://mariadb.com/kb/en/installing-and-using-mariadb-via-docker/
- OpenAI 嵌入 https://platform.openai.com/docs/guides/embeddings
- OpenAI Chat Completions https://platform.openai.com/docs/guides/text-generation
- 使用的编码工具:Cursor (https://cursor.ac.cn/) 结合 Claude 3.5 Sonnet 以及 Black (https://pypi.ac.cn/project/black/)