标签归档: GenAI

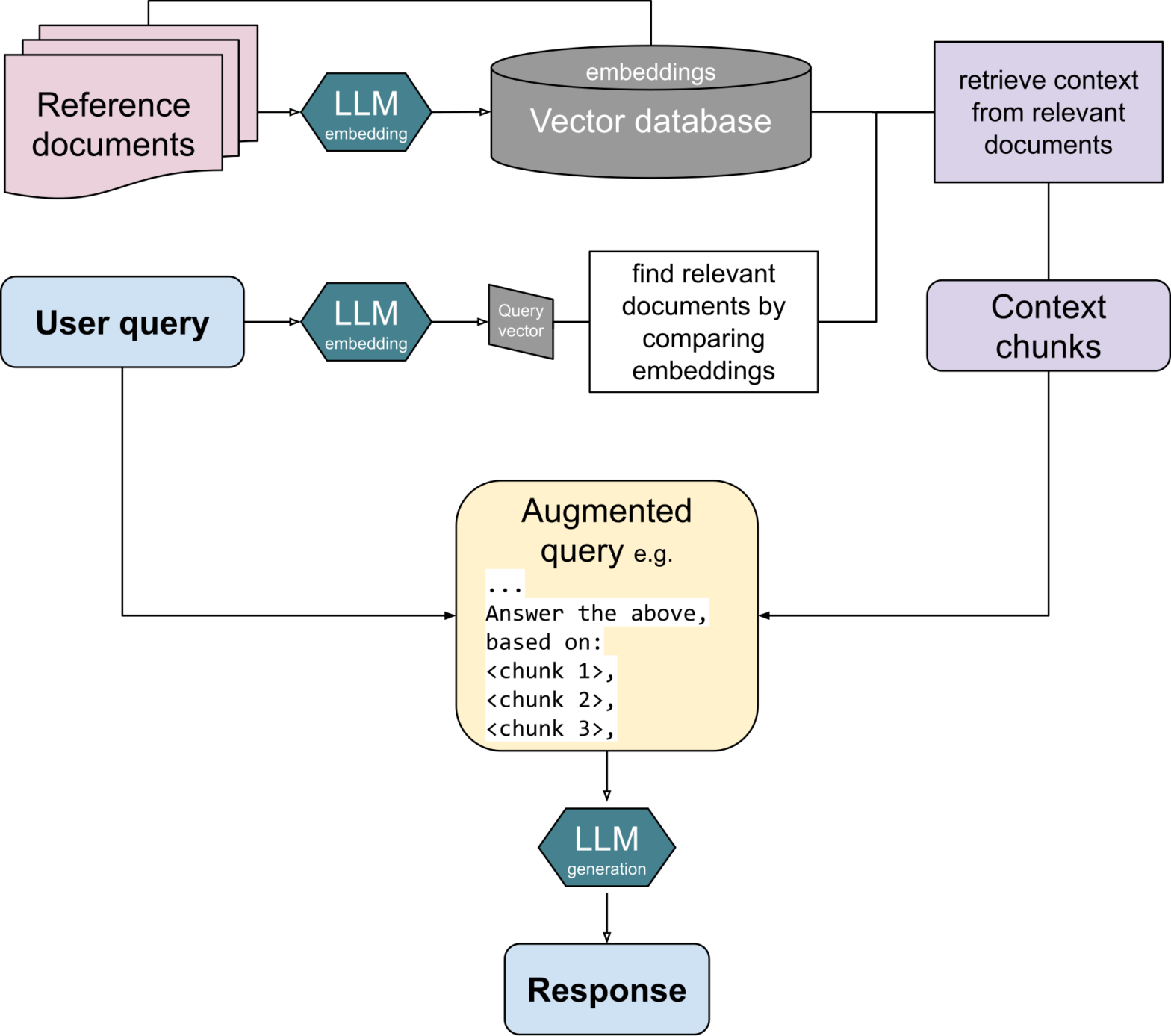
MariaDB 人工智能 RAG 黑客松的创意阶段即将于周一(三月底前)截止。
目前我们收到了几个很棒的提交。一个关于结合知识图谱和 LLM,使用 MariaDB Vector 最近邻搜索。另一个关于“高级上下文差异”,它不是根据文字本身,而是根据内容识别两个文本语料库之间的差异。
所有目前的提交都在创新赛道。我们特别希望集成赛道的提交 – 将 MariaDB 添加到像这些框架或其他应用中。
…
参加使用 MariaDB Vector 和 Python 的人工智能 RAG 黑客松还剩一周时间!
获胜者将在五月的赫尔辛基 Python 见面会上进行演示,获得 MariaDB 基金会和 Open Ocean Capital 的荣誉和宣传,以及芬兰 verkkokauppa.com 的奖品。
要参与,请组建一个团队(1-5 人)并在三月底前为两个赛道之一提交一个想法。然后您有时间直到 5 月 5 日来开发您的想法,之后是 5 月 27 日的见面会。
- 集成赛道: 在现有的开源项目或人工智能框架中启用 MariaDB Vector。
…