标签存档: LLM

距离加入使用 MariaDB Vector 和 Python 的 AI RAG 黑客马拉松仅剩一周!
获胜者将在五月的赫尔辛基 Python meetup 上进行演示,获得 MariaDB 基金会和 Open Ocean Capital 的荣誉和宣传,以及芬兰 verkkokauppa.com 提供的奖品。
要参与,请组建一个团队(1-5人),并在三月底之前提交其中一个赛道的想法。然后您有时间到 5 月 5 日来开发该想法,之后 meetup 将于 5 月 27 日举行。
- 集成 赛道:在现有的开源项目或 AI 框架中启用 MariaDB Vector。
…
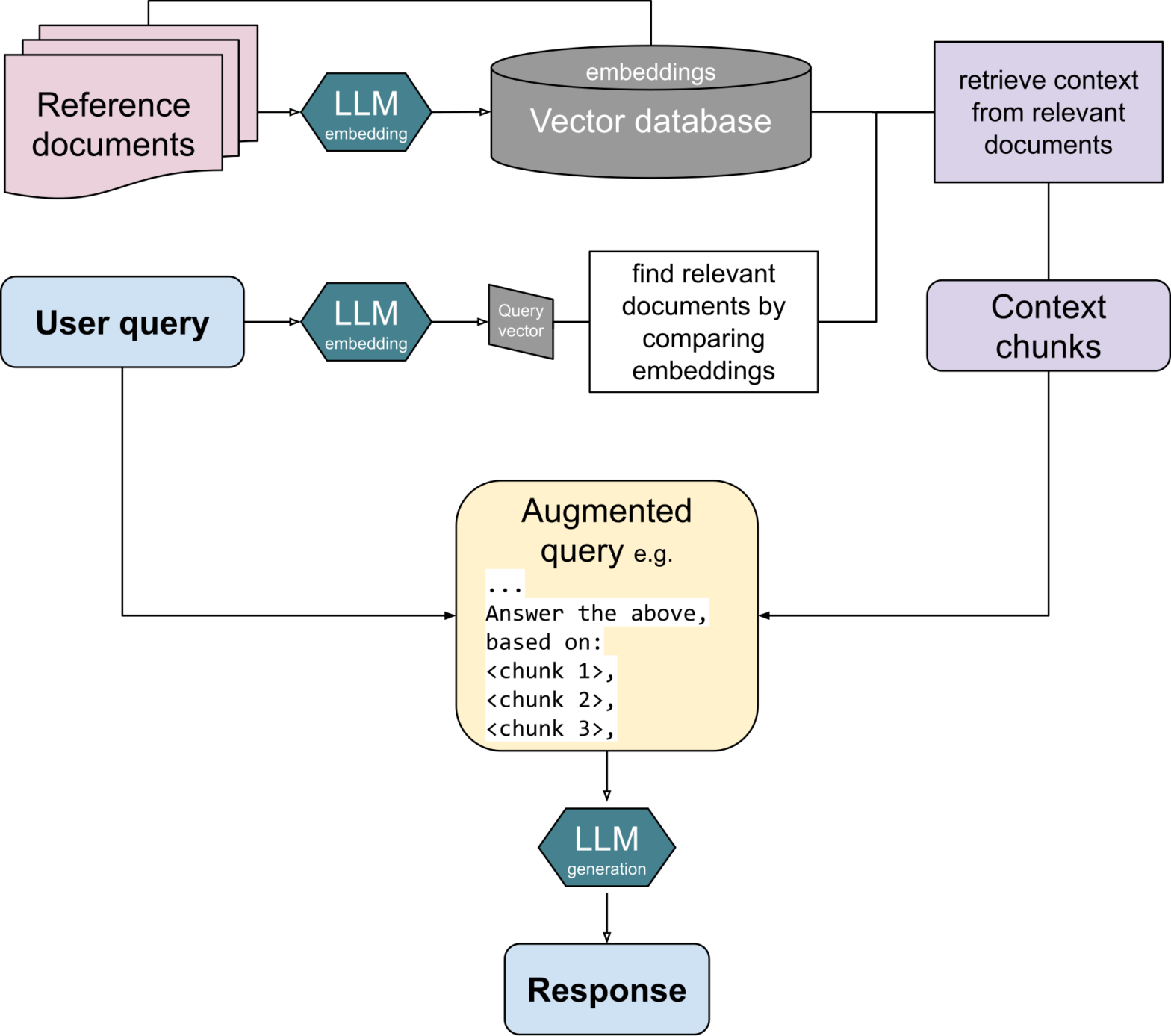


我们来了,我们是开源的,并且我们为您提供了基于 RDBMS 的向量搜索!随着 MariaDB 11.6 Vector 预览版的发布,MariaDB Server 生态系统终于可以体验期待已久的 MariaDB Server 向量搜索功能如何工作了。这项工作是 MariaDB plc、MariaDB 基金会员工以及贡献者,尤其是来自 Amazon AWS 的贡献者共同协作的结果。
“MariaDB Vector”回顾
如果您是向量新手,这是目前为止发生的事情
- 我们多次撰写博客,阐述了我们关于生成式 AI 在 MariaDB Server 中应处于何处位的观点
- 我们在二月份的 FOSDEM 边缘活动中展示了第一个演示
- 我们在 mariadb.org/projects/mariadb-vector/ 上启动了一个项目页面,其中包含多个视频
- 我们在伦敦的 Intel Vision 活动中登台,主题是“AI 无处不在”
- 我们在一篇题为“MariaDB 也即将成为向量数据库”的博客中,介绍了 Amazon 对向量和 MariaDB 的看法
重点:MariaDB Vector 已准备好进行实验
…